[AFL II]whitepaper
这个白皮书是站在一个开发者角度写的, 不是站在使用者的角度写的
因此有一些句子读起来特别象黑话, 看不懂的, 只有看了源码分析了算法, 才知道作者为什么要那样说
并且写的比较啰嗦, 举例子就能说明的事情非得嗯讲道理
我去网上看其他人的翻译, 也是很多看不懂的地方
总之在我一眼没看AFL源码时看这个白皮儿书看的是一头雾水
看过源码的部分能够转换成通俗的比喻, 没看过的是真看不懂在说什么
我是诗人, 这白皮书就史诗
下面请大家欣赏史
本文提供一个对 AFL的概览视角
虽然作者是这样说的, 但是我觉得是一个事后诸葛亮的概览视角
研究动机和设计目标移步lcamtuf.coredump.cx/afl/historical_notes.txt
0.设计说明
这一节是纯装逼的, 看都不看
得益于轻量级的插桩技术, AFL的各种优点才能发扬光大, 然此仅为一家之言, 不应该被奉为圭臬.
快速可靠易用才是唯一准则
1.覆盖率收集
插桩的目的是记录粗粒度的执行路径的触发次数.
这我有个疑问, 对于不知道插桩实现细节的读者, 这里直接放这段伪代码, 能看懂吗?
在分支入口点注入的桩代码,其伪代码如下:
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
其中 cur_location图省事儿随机哈希生成,并保持了异或输出的均匀分布,但这还是可能会导致碰撞
shared_mem是一个 64KB的共享内存区,由 afl-fuzz创建, 映射给目标程序使用.
该共享内存区上有一个位图数据结构, 用来记录执行路径的命中次数.
该位图的大小, 以尽量不发生哈希碰撞为宜, 并且尽量小, 最好是能整个装进 L2缓存
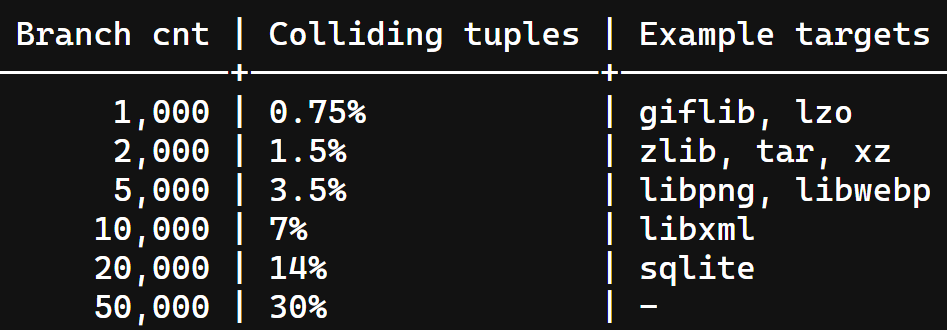
作者举了个例子, 列表分析了一下分支数量和哈希碰撞的关系, 意思是10000个分支以下的程序还是能拿捏的.
相对于只记录代码块的覆盖率, 这种记录执行路径的方法能够记录更详细的信息. 举例来说
上述两条路径包含的代码块完全相同,但是执行路径有别.
记录执行路径更容易发现蛛丝马迹,因为漏洞通常和非预期的或者错误的状态转义有关,而不是单纯到达新的基本块.
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
在这段伪代码中, 最后一行将 prev_location右移一位, 其意义是:
假如没有这个右移, 那么 A^B=B^A, 这就意味着 A->B和 B->A两个执行路径, 在命中计数上看不出区别来,
更甚者, 假设有循环A和循环B, 那么 A^A=B^B=0.
因此将 prev_location右移一位, 此时命中计数就带有了执行方向信息.
由于 Intel CPU缺少饱和算术指令, 这导致命中计数可能会上溢绕回到 0.但是这不太可能发生,因此可以接受.
这种话真没必要说吧, 就好比说“人被猫杀死的可能性很小, 但不是0”
并且哥们在此之前是不知道“饱和算术指令”这么牛逼的东西的, 还得让哥们去查, 就是算满了不回绕呗
2.发现新行为
fuzzer使用共享内存记录执行路径的命中情况, 监控是否出现了新行为.
有两种情况下认为发现了新行为:
1.直接发现了新的元组
2.一个元组的重复次数足以让fuzzer引起重视
举两个例子:
这里2号路径就被认为是新的执行路径,因为引入了新的元组 <C,A><A,E>
那么下面3号路径就不是新的执行路径,因为没有发现新的元组
除了检查新的元组, fuzzer还会统计元组的命中次数, 依据命中次数用几个桶子记录
一个元组在命中1,2,3,4次时都认为是新行为.
但是第5次和第6次就有点鸡肋了
第7次到第8次时, fuzzer才会认为这个元组还是有点东西的, 还能再好奇一下
fuzzer会使用造成新行为的输入作为语料
3.进化输入队列
4.筛选语料
5.裁剪输入文件
作者在这里概述了一下
afl-tmin裁剪输入的过程, 我觉得还是有些冗杂,我们只关心一个庞大的输入字符串, 最后如何精简到几个字节,
这个过程是很神奇的, 应该有一些别出心裁的算法, 你直接把算法端上来就完了.
裁剪手段有四个
块标准化: BLOCK NORMALIZATION
将输入划分为等大小的块, 按照从前往后的顺序, 每次拿一块将块内字符全都置‘0’字符, 然后作为输入, 执行目标程序, 如果不影响执行路径, 则该块可以被标准化, 也就是块内全部置‘0’
块标准化只会执行一次, 但是下面三个过程会重复执行直到收敛
块删除: BLOCK DELETION
将输入划分为等大小的块,按照从前往后的顺序, 每次拿一个块扬了, 剩下的拼起来作为输入, 执行目标程序, 如果不影响执行路径, 则该块可以删除.
从前到后一轮结束后, 对于剩下不能删除的块, 尝试将步长减半, 重新尝试小块小块地删除.
重复上述过程直到步长减到1并且一块也删不掉了. 就认为收敛了.
非零字母种类数最小化: ALPHABET MINIMIZATION
遍历256个ASCII字符, 每次选定一个字符 ,将输入中所有该字符替换为‘0’, 作为输入, 执行目标程序 , 如果不影响执行路径, 则该字符可以被全部替换
比如ABCDACC, 以A为目标字符, 替换完后是0BCD0CC, 以此作为输入, 观察执行路径
非零字母个数最小化: CHARACTER MINIMIZATION
在ALPHABET MINIMIZATION中可能会出现如下情况:
某个输入
A...A…, 其中只有第一个A会影响执行路径, 后面的A不影响, 但是在ALPHABET MINIMIZATION中, 一类字符是荣辱与共的, 所有A都因为第一个A而无法删除.因此在本CHARACTER MINIMIZATION过程中, 将以更细的粒度, 也就是逐个字节更换为‘0’进行尝试
CHARACTER MINIMIZATION执行完毕后再重复BLOCK DELETION -> ALPHABET MINIMIZATION -> CHARACTER MINIMIZATION这个过程
直到一整个流程中没有对输入的任何改动, 认为最终收敛了, 可以不折腾了